When
using Oracle SOA Suite 11g SCA Spring Bean components you will
likely be facing a decision about how to interact with your database from
within the Spring Beans. The answer will ultimately depend on your overall
system architecture. For instance you may wire a Spring Bean directly to
a DB adapter, or you can encapsulate the data access inside a web service or an EJB session bean. In my last project we
have decided to access the data
directly from the Spring Beans,
taking advantage of the flexibility provided by Spring's JDBC abstraction framework. In fact Spring makes JDBC access so simple that it is easy to miss
other alternatives, one of them being especially noteworthy - the Java Persistence API.
Java Persistence API
has greatly simplified the object-relational mapping in Java. Let's have a look
at how JPA can be incorporated into an SCA application.
The Service
We will create a
simple service inspired by my other passion, motorcycles. The service will
provide these operations:
- createBike - creates an entity for a motorcycle with the specified manufacturer and model name and returns the entity's ID.
- getBikeDescription - retrieves the description of a motorcycle with the specified ID.
The Project
We start with an
empty composite project and add a Spring Bean, following the code-first
approach:
- Create a Java interface for our SCA service: MotoService.java
- Create a dummy implementation of the above interface MotoServiceImpl.java.
- Create a Spring Context which uses the classes created in the above steps.

- Wire the Spring Context to the Exposed Services lane - this step will generate MotoService.wsdl.


JPA Artifacts
To enable our SCA
project for JPA, we follow these steps:
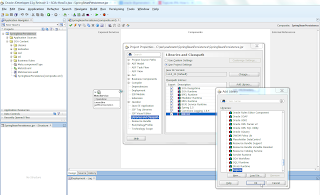
- Add two predefined JDeveloper libraries to the project dependencies: EJB 3.0 and TopLink.

- Create the entity class: Bike.java. Note that the class is not Serializable - it does not need to be (more on the topic here). The DDL to the create the SQL objects for the Bike entity is in create_tables.sql.
- Create the DAO class: BikeDao.java. Note that the EntityManager field does not have the usual @PersistenceContext annotation. This is because we will use Spring Bean wiring to inject the property (see section Configure the Entity Manager below).
- Create the JPA persistence definition: persistence.xml. If you plan on running the example project in your environment you will need to modify the jta-data-source property to match a JNDI data source configured in your WebLogic server instance.
Wire the Spring Bean to JPA
Now we can wire the
JPA classes to the service Spring Bean:
- Change the MotoServiceImpl.java implementation to use the DAO.
- Add the BikeDao property to MotoSB.xml:

Configure the Entity Manager
Now we need to
configure the entity manager by explicitly injecting it to the DAO class:

Since we need to
inject an entity manager to the DAO class, we use a SharedEntityManagerBean to create an entity manager from the
entity manager factory. If you try to create the entity manager
programmatically - by calling the factory's createEntityManager
method, as I did :-) - the entity manager will not bind itself to the
transaction and as a result, the database changes will not be committed.
Configure Transactions
Finally, we will
declaratively enhance the service Spring Bean with the transaction behavior -
by using a
TransactionProxyFactoryBean wrapper:

Note that the above
approach gives you full control over the transaction behavior of the Spring
Bean component. This is much more flexible than the transaction semantics of BPEL and Mediator components.
Deploy and Test
That's it. The
project is now ready to deploy and test. I tested with soapUI (project available here) by creating an entry for my favorite motorcycle (KTM Enduro
690R) and retrieving its description afterwards.

Conclusion
In
the above I have shown how to integrate JPA with SCA Spring Beans. The ability
to use JPA makes Spring Beans a great alternative to another
SCA components which are limited to data access via a DB Adapter or an encapsulated service. As a matter of fact, you can add pure data access Spring Beans to your toolbox and use them to
facilitate data access from another SCA components. Choosing the right SCA component type is a topic in itself and it has been addressed in this excellent blog of my former colleague
Alex Suchier.
If you want to try
the Spring Bean JPA integration for yourself, you can get the project fromSubversion or download it as a 7-zip
archive.






